Analysis 5: Difference between revisions
No edit summary |
No edit summary |
||
| Line 1: | Line 1: | ||
[[2012 | Back to 2012 Main Page]] | [[2012 | Back to 2012 Main Page]] | ||
In the past few tutorials, you learned how to fit data using a linear model. While many datasets may be fit with such a model, other datasets, including some that you encounter in the lab course, will not be described by linear models. Remember that a model is linear if it is linear in the parameters, so a nonlinear model must be nonlinear in the parameters. When fitting a nonlinear model, there is generally no analytic solution to the <math>chi^2</math> minimization problem. Instead, a numerical technique is used to explore parameter space in search of the <math>chi^2</math> minimum. A standard technique is to start at some point in parameter space and follow the gradient of the function towards the minimum, also using information about the curvature, where useful. A standard algorithm is called the Levenburg-Marquardt algorithm which uses the gradient and Hessian of the <math>chi^2</math> to find the best fit values and their associated variance. You can learn more about this by reading the associated sections in Press, Teukolsky, Vetterling, Flannery, Numerical Recipes in C (Available online). Also you can check out the associated section in my notes from from last year [[media: Data_reduction_notes.pdf]]. Instead of diving into the details here, we provide a worked example. | In the past few tutorials, you learned how to fit data using a linear model. While many datasets may be fit with such a model, other datasets, including some that you encounter in the lab course, will not be described by linear models. Remember that a model is linear if it is linear in the parameters, so a nonlinear model must be nonlinear in the parameters. When fitting a nonlinear model, there is generally no analytic solution to the <math>\chi^2</math> minimization problem. Instead, a numerical technique is used to explore parameter space in search of the <math>\chi^2</math> minimum. A standard technique is to start at some point in parameter space and follow the gradient of the function towards the minimum, also using information about the curvature, where useful. A standard algorithm is called the Levenburg-Marquardt algorithm which uses the gradient and Hessian of the <math>\chi^2</math> to find the best fit values and their associated variance. You can learn more about this by reading the associated sections in Press, Teukolsky, Vetterling, Flannery, Numerical Recipes in C (Available online). Also you can check out the associated section in my notes from from last year [[media: Data_reduction_notes.pdf]]. Instead of diving into the details here, we provide a worked example. | ||
The following example is carried out using the python programming language. A great collection of python tools are downloadable for free (since you are students) here: [http://www.enthought.com/products/edudownload.php] | The following example is carried out using the python programming language. A great collection of python tools are downloadable for free (since you are students) here: [http://www.enthought.com/products/edudownload.php] | ||
| Line 9: | Line 9: | ||
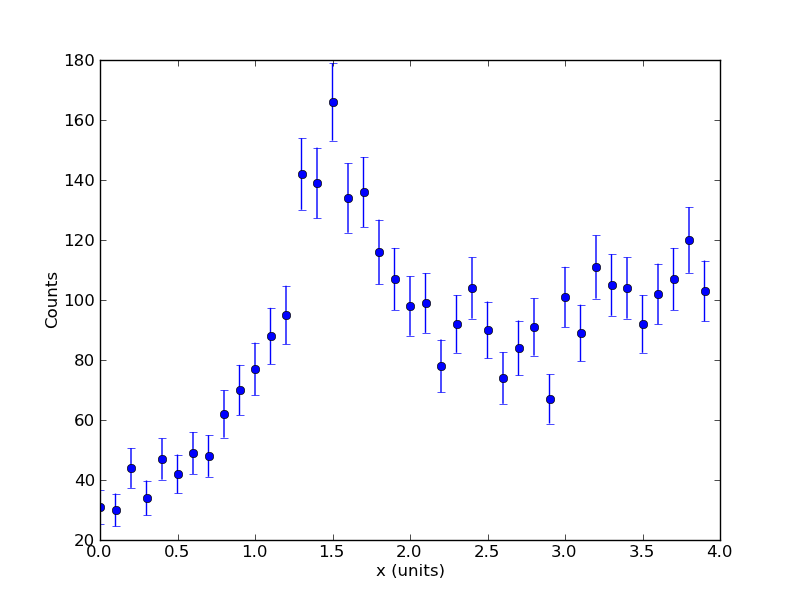
Here we introduce some data <math>c_i</math> representing, say, the number of gamma-rays incident on a detector. These data are sorted by their energy <math>e_i</math>. We model the counts as a function of their energy: | Here we introduce some data <math>c_i</math> representing, say, the number of gamma-rays incident on a detector. These data are sorted by their energy <math>e_i</math>. We model the counts as a function of their energy: | ||
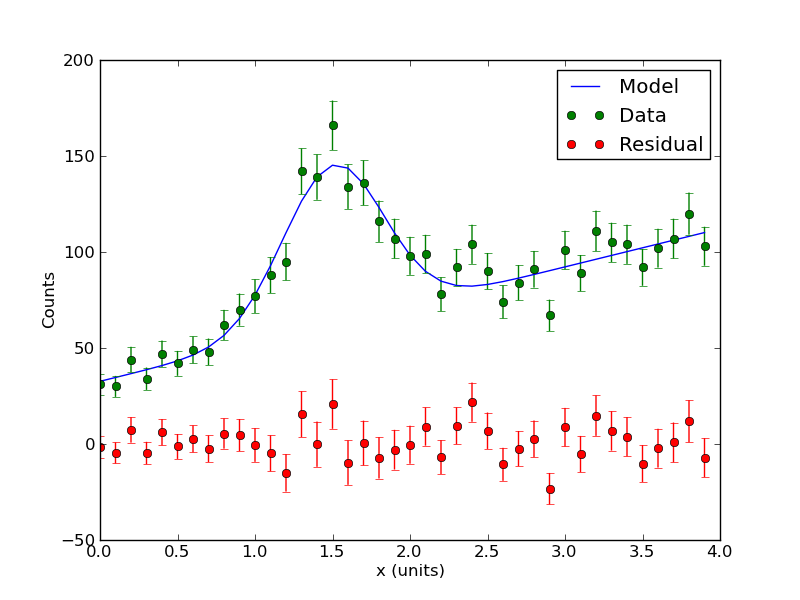
<math> c_i = A \exp(-(e_i-B)^2/(2 C^2)) + | <math> c_i = A \exp(-(e_i-B)^2/(2 C^2)) + Dx + E </math> | ||
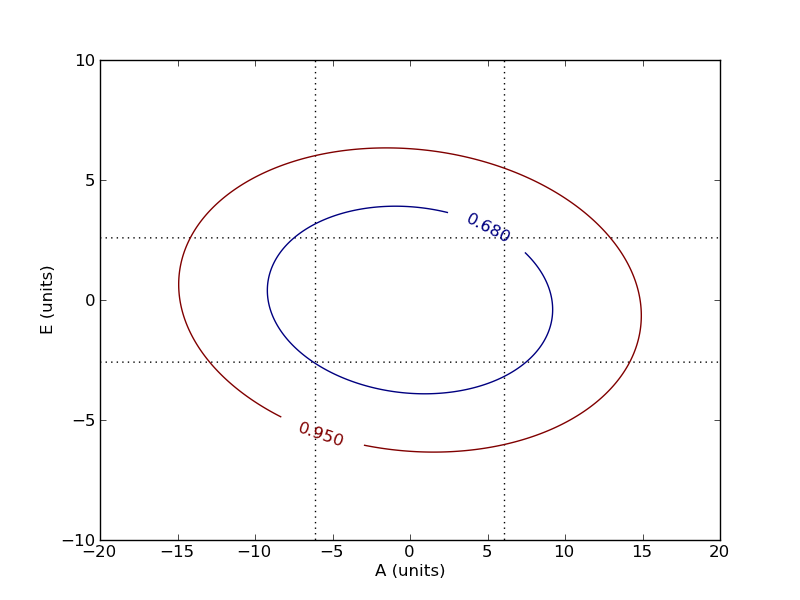
Here the parameters are the amplitude A, offset B, and width C of a Gaussian peak -- presumably modeling some emission line in the data. There is also a linear background with slope D and offset E. This example is particularly relevant to the nuclear spectroscopy lab. Because this is count data, we can use Poisson statistics to estimate the variance of the data: the variance of <math>c_i</math> is just <math>c_i</math>. | |||
Revision as of 01:03, 11 February 2012
In the past few tutorials, you learned how to fit data using a linear model. While many datasets may be fit with such a model, other datasets, including some that you encounter in the lab course, will not be described by linear models. Remember that a model is linear if it is linear in the parameters, so a nonlinear model must be nonlinear in the parameters. When fitting a nonlinear model, there is generally no analytic solution to the <math>\chi^2</math> minimization problem. Instead, a numerical technique is used to explore parameter space in search of the <math>\chi^2</math> minimum. A standard technique is to start at some point in parameter space and follow the gradient of the function towards the minimum, also using information about the curvature, where useful. A standard algorithm is called the Levenburg-Marquardt algorithm which uses the gradient and Hessian of the <math>\chi^2</math> to find the best fit values and their associated variance. You can learn more about this by reading the associated sections in Press, Teukolsky, Vetterling, Flannery, Numerical Recipes in C (Available online). Also you can check out the associated section in my notes from from last year media: Data_reduction_notes.pdf. Instead of diving into the details here, we provide a worked example.
The following example is carried out using the python programming language. A great collection of python tools are downloadable for free (since you are students) here: [1]
Nonlinear Model Example
Here we introduce some data <math>c_i</math> representing, say, the number of gamma-rays incident on a detector. These data are sorted by their energy <math>e_i</math>. We model the counts as a function of their energy:
<math> c_i = A \exp(-(e_i-B)^2/(2 C^2)) + Dx + E </math>
Here the parameters are the amplitude A, offset B, and width C of a Gaussian peak -- presumably modeling some emission line in the data. There is also a linear background with slope D and offset E. This example is particularly relevant to the nuclear spectroscopy lab. Because this is count data, we can use Poisson statistics to estimate the variance of the data: the variance of <math>c_i</math> is just <math>c_i</math>.
Here is the data for non-linear model and confidence interval example: media:counts.txt. The first column is energy, the second column is counts.
Here is the code (change sufixx to .py): media:Nonlinear_model.txt. The Output media:Data_nonlinear.png, media:Counts_with_fit.png, media:Confidence_peak_constant_background.png
{kind=link}
{kind=link}
{kind=link}